
How Small Language Models Shape a Human-Driven Data Economy
Key Insights from Nick Havryliak, Co-founder & CEO, Assisterr

As we prepare for our upcoming AI x Web3 dAGI Summit in Bangkok, we’re looking back at the key takeaways from our previous conference.
One of our featured speakers, Nick Havryliak, Co-founder & CEO of Assisterr, explored the future potential of small language models (SLMs) and their strategic role in creating a human-centric data economy.
The talk was rich with expert insights into the limitations of large models, the importance of specialized data, and innovative solutions to persistent data challenges. Below, we present the key insights from Nick's talk.
🇹🇭 Only 1 week left until our dAGI Summit in Bangkok!

Gain insights into the future of AI, from decentralized training and collaborative intelligence to blockchain-powered scaling of ML models.
Expect:
- 20 industry leaders
- 300 attendees
- Keynotes, panels, and one-on-one meeting with experts
📅 November 11, Bangkok
The Scarcity of High-Quality, Domain-Specific Data
One of the primary challenges in AI development today is the lack of unique, high-quality data tailored to specific applications. Large language models have been trained on vast datasets sourced from publicly available content, like Wikipedia and general internet archives.
However, as these reservoirs are depleted, the need for specialized, domain-specific data becomes more pronounced. Traditional data harvesting techniques struggle to fill this gap, limiting the effectiveness of these expansive models in niche or complex industries.
The industry must pivot from a quantity-driven data strategy to one that prioritizes data quality. Well-curated, domain-specific data is essential to unlocking the full potential of smaller, more efficient models.
Why Small Language Models Are Gaining Traction

Small language models are emerging as a compelling alternative, especially when trained or fine-tuned using high-quality, domain-relevant data. With significant cost savings, SLMs can achieve performance comparable to or better than LLMs in certain tasks.
Economic and Practical Advantages: Smaller models require fewer computational resources and can be more easily customized for specific use cases. They can also be updated more frequently, making them agile tools for industries that need rapid adaptation.
Performance and Efficiency: Research has shown that with the right data "layering," SLMs can outmatch larger models, proving that size isn't everything when it comes to AI performance.
The "Last Mile Challenge" and the Need for Trusted Data
Havryliak introduced the concept of the “Last Mile Challenge,” which refers to the difficulties of acquiring specialized information after exhausting broad, easily accessible datasets. This challenge is particularly pronounced in industries like law, healthcare, and finance, where nuanced, high-stakes data is crucial.
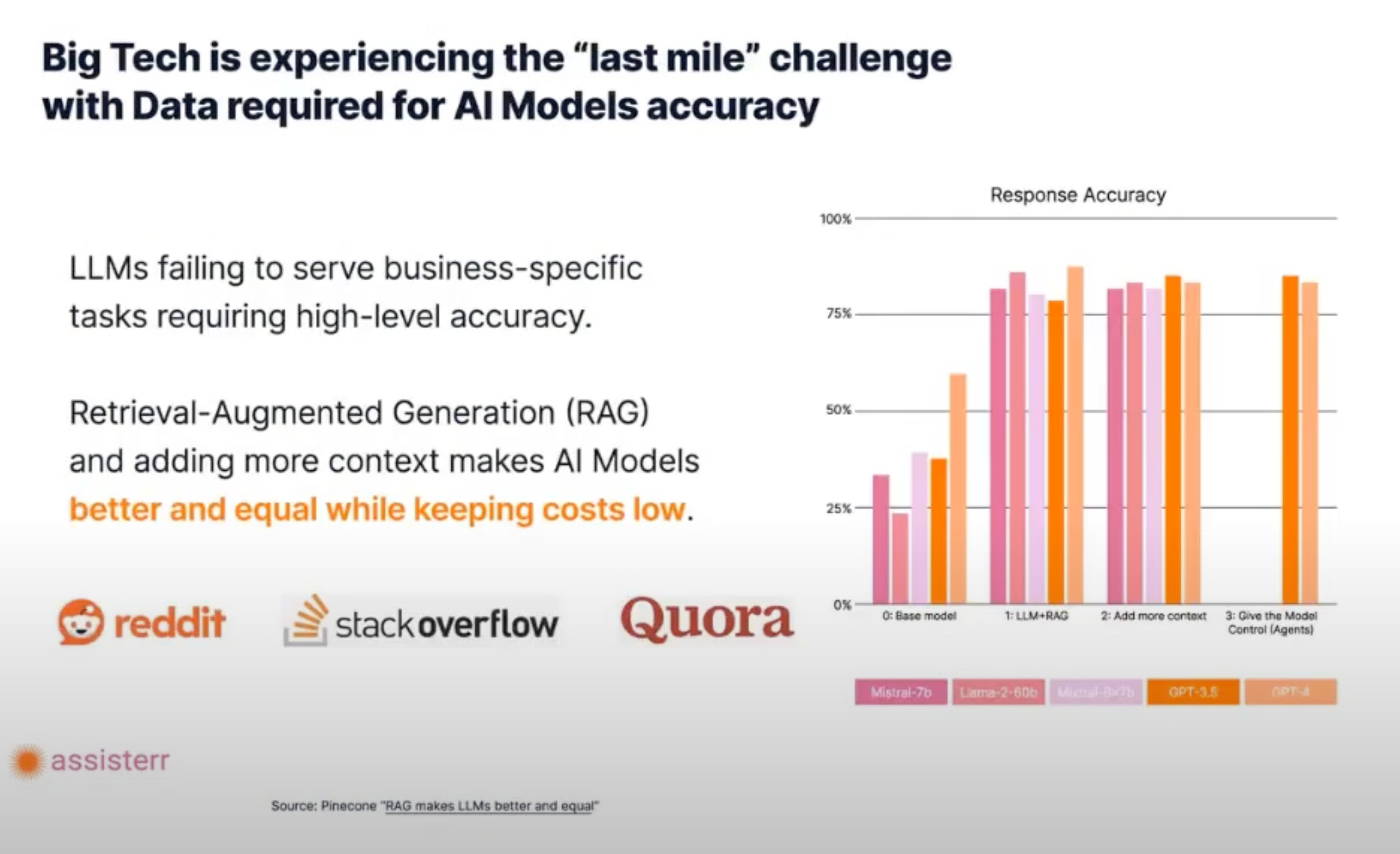
A legal AI system may have access to public case law but lack the proprietary data from specific firms that could refine its predictive accuracy. Bridging this gap requires innovative data collection and curation strategies.
To tackle these data challenges, one promising method is the Retrieval-Augmented Generation. RAG enhances small models by selectively retrieving and utilizing domain-specific data instead of undergoing costly, full-scale retraining. This technique has gained traction as it optimizes model performance with precision data without inflating infrastructure demands.
By layering high-quality data onto a pre-trained SLM, companies can efficiently address information gaps. This approach also ensures that data remains relevant and impactful, making AI systems more reliable and useful for end users. Yet, to truly harness the power of SLMs, ensuring the integrity and ethical management of data is just as crucial.
Building a Fair and Transparent Data Economy
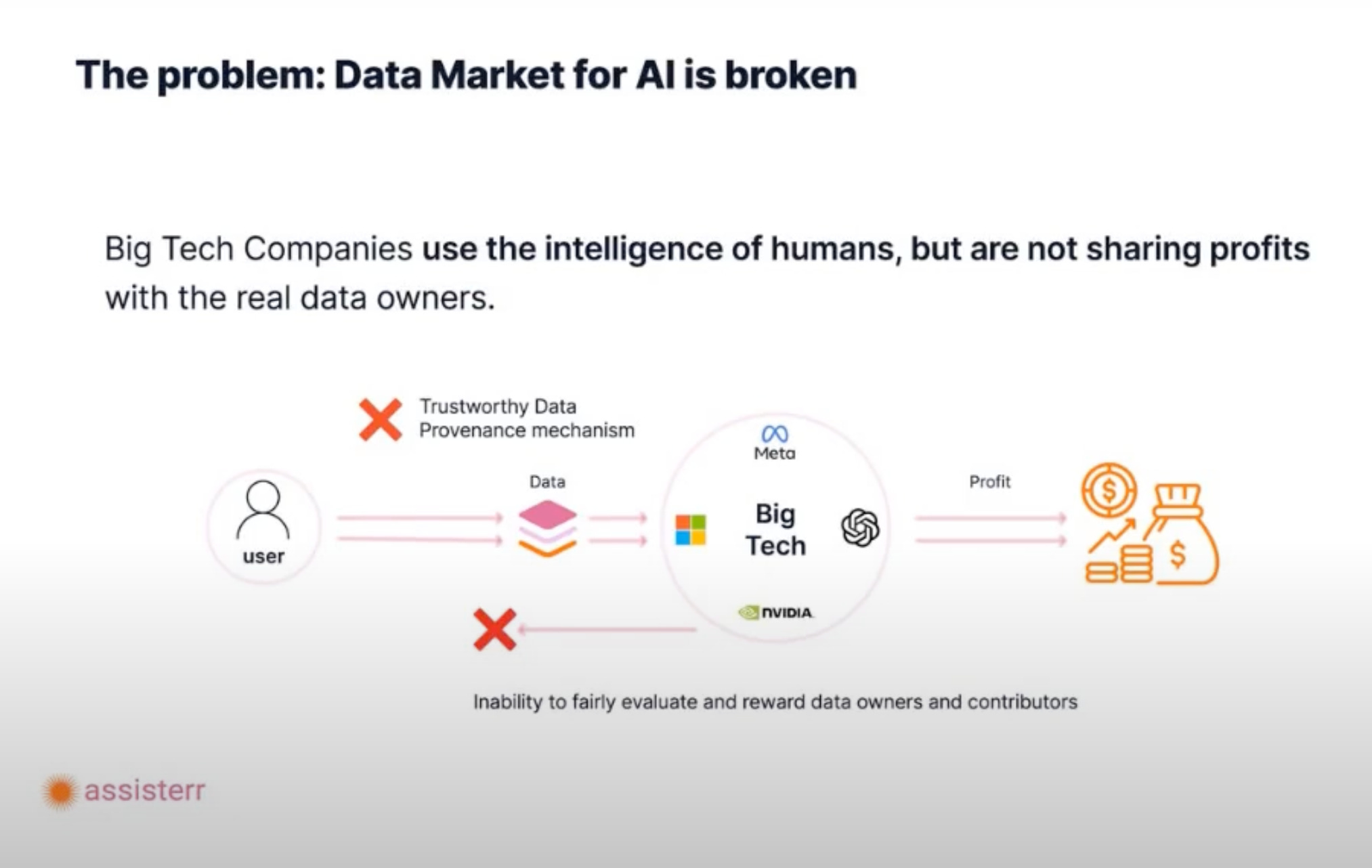
Creating a human-driven data economy requires rethinking how data is contributed, validated, and monetized. A major theme Havryliak emphasized was the importance of data provenance — tracking the origin and impact of every data point. Transparent systems are essential for ensuring that contributors understand how their data is used and compensated fairly.
He highlighted models where communities participate in filling data gaps and validating contributions. This creates an incentive structure that rewards quality input and fosters active engagement.
The future may see more platforms compensating contributors not just as data providers but as active stakeholders in AI ecosystems, driving a more ethical and participatory data landscape.
On-Chain Data Provenance
One of the standout solutions discussed was the use of on-chain data provenance protocols to establish a transparent, trustworthy foundation for data usage and compensation. By leveraging blockchain technology, these protocols ensure that the origin, integrity, and usage of each data point are easily verifiable.
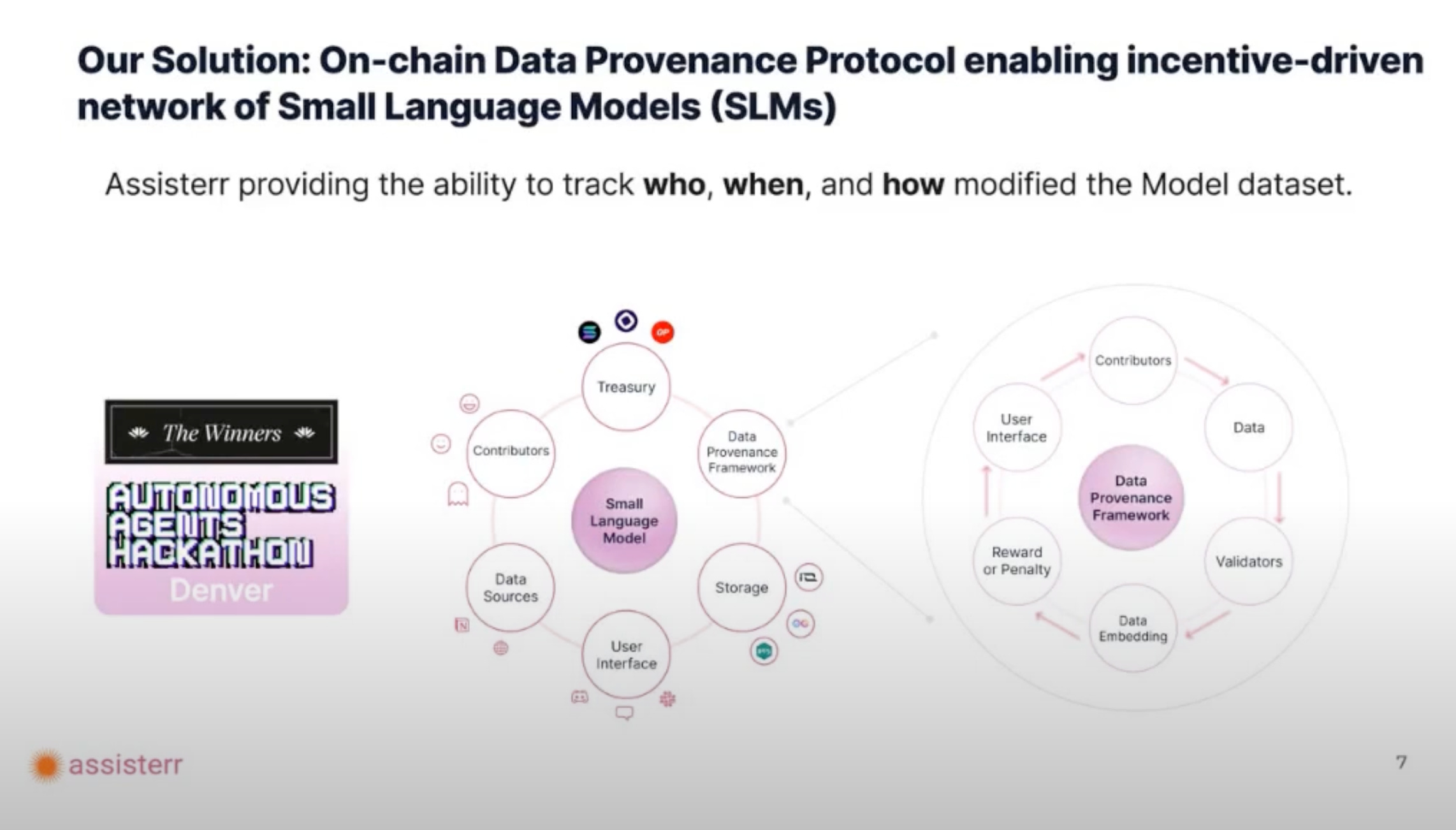
On-chain data provenance involves recording the history of each piece of data on a decentralized ledger. This immutable record ensures that contributors can trace how their data is utilized, from initial contribution to AI model integration and beyond.
Benefits for Data Contributors: These protocols empower data contributors, giving them visibility into where and how their data is used and ensuring they are compensated fairly based on actual usage and impact. It also fosters trust by making data transactions transparent and tamper-proof.
Economic Implications: Such a system could reshape the data economy, incentivizing quality data contributions while discouraging unethical data practices. With on-chain verification, businesses and organizations can also prove the legitimacy of their data sources, which is crucial for applications in regulated industries like finance and healthcare.
Platforms like Assisterr are already utilizing these concepts by providing AI-driven data marketplaces built on on-chain provenance. By integrating blockchain, Assisterr ensures data ownership is protected and contributors are rewarded transparently.
This approach not only addresses data mismanagement issues but also creates a more equitable economic model where every contributor’s impact is measurable and rewarded.
SLMs offer scalable, efficient solutions tailored to unique challenges. These use cases demonstrate that AI success doesn’t always mean building bigger models but rather building smarter ones.
The shift from LLMs to SLMs is not just a technological evolution but a strategic shift toward efficiency, ethical data use, and sustainability in AI development.
Next week, Nick Havryliak will be speaking at the dAGI Summit in Bangkok on “Navigating the Matrix: How Community-Owned Intelligence Will Power the Agent Economy.”
That wraps it up for today! 👋 But before you go...
Check out our LinkedIn or Twitter pages for more details. Follow us to stay updated on all the latest news!
Best,
Epic AI team.